Submissions





GlyTouCan
Glycan Structure Repository
GlyComb
Glycoconjugate Repository
GlycoPOST
Glycomics MS raw data Repository
UniCarb-DR
Glycomics MS Repository for glycan annotations from GlycoWorkbench
LM-GlycoRepo
Repository for lectin-assisted multimodality dataAll Resources
Genes / Proteins / Lipids Glycans / Glycoconjugates Glycomes Pathways / Interactions / Diseases / OrganismsTools
Guidelines
MIRAGE
 Low-density lipoprotein receptor-related protein 1B
Low-density lipoprotein receptor-related protein 1B
Summary
- UniProt ID
- Q9NZR2
- Gene Symbol
-
- LRP1B
- LRPDIT
- Gene ID
- 53353
- Organism
- Homo sapiens (human)
Annotation
- Keyword
-
- Calcium
- Disulfide bond
- EGF-like domain
- Endocytosis
- Glycoprotein
- Proteomics identification
- Receptor
- Reference proteome
- Repeat
- Signal
- Transmembrane helix
- Gene Ontology (GO)
| GO Term |
|---|
| plasma membrane |
| receptor complex |
| GO Term |
|---|
| protein transport |
| receptor-mediated endocytosis |
| GO Term |
|---|
| calcium ion binding |
| low-density lipoprotein particle receptor activity |
Sequence
MSEFLLALLTLSGLLPIARVLTVGADRDQQLCDPGEFLCHDHVTCVSQSWLCDGDPDCPDDSDESLDTCPEEVEIKCPLNHIACLGTNKCVHLSQLCNGVLDCPDGYDEGVHCQELLSNCQQLNCQYKCTMVRNSTRCYCEDGFEITEDGRSCKDQDECAVYGTCSQTCRNTHGSYTCSCVEGYLMQPDNRSCKAKIEPTDRPPILLIANFETIEVFYLNGSKMATLSSVNGNEIHTLDFIYNEDMICWIESRESSNQLKCIQITKAGGLTDEWTINILQSFHNVQQMAIDWLTRNLYFVDHVGDRIFVCNSNGSVCVTLIDLELHNPKAIAVDPIAGKLFFTDYGNVAKVERCDMDGMNRTRIIDSKTEQPAALALDLVNKLVYWVDLYLDYVGVVDYQGKNRHTVIQGRQVRHLYGITVFEDYLYATNSDNYNIVRINRFNGTDIHSLIKIENAWGIRIYQKRTQPTVRSHACEVDPYGMPGGCSHICLLSSSYKTRTCRCRTGFNLGSDGRSCKRPKNELFLFYGKGRPGIVRGMDLNTKIADEYMIPIENLVNPRALDFHAETNYIYFADTTSFLIGRQKIDGTERETILKDDLDNVEGIAVDWIGNNLYWTNDGHRKTINVARLEKASQSRKTLLEGEMSHPRGIVVDPVNGWMYWTDWEEDEIDDSVGRIEKAWMDGFNRQIFVTSKMLWPNGLTLDFHTNTLYWCDAYYDHIEKVFLNGTHRKIVYSGRELNHPFGLSHHGNYVFWTDYMNGSIFQLDLITSEVTLLRHERPPLFGLQIYDPRKQQGDNMCRVNNGGCSTLCLAIPGGRVCACADNQLLDENGTTCTFNPGEALPHICKAGEFRCKNRHCIQARWKCDGDDDCLDGSDEDSVNCFNHSCPDDQFKCQNNRCIPKRWLCDGANDCGSNEDESNQTCTARTCQVDQFSCGNGRCIPRAWLCDREDDCGDQTDEMASCEFPTCEPLTQFVCKSGRCISSKWHCDSDDDCGDGSDEVGCVHSCFDNQFRCSSGRCIPGHWACDGDNDCGDFSDEAQINCTKEEIHSPAGCNGNEFQCHPDGNCVPDLWRCDGEKDCEDGSDEKGCNGTIRLCDHKTKFSCWSTGRCINKAWVCDGDIDCEDQSDEDDCDSFLCGPPKHPCANDTSVCLQPEKLCNGKKDCPDGSDEGYLCDECSLNNGGCSNHCSVVPGRGIVCSCPEGLQLNKDNKTCEIVDYCSNHLKCSQVCEQHKHTVKCSCYEGWKLDVDGESCTSVDPFEAFIIFSIRHEIRRIDLHKRDYSLLVPGLRNTIALDFHFNQSLLYWTDVVEDRIYRGKLSESGGVSAIEVVVEHGLATPEGLTVDWIAGNIYWIDSNLDQIEVAKLDGSLRTTLIAGAMEHPRAIALDPRYGILFWTDWDANFPRIESASMSGAGRKTIYKDMKTGAWPNGLTVDHFEKRIVWTDARSDAIYSALYDGTNMIEIIRGHEYLSHPFAVSLYGSEVYWTDWRTNTLSKANKWTGQNVSVIQKTSAQPFDLQIYHPSRQPQAPNPCAANDGKGPCSHMCLINHNRSAACACPHLMKLSSDKKTCYEMKKFLLYARRSEIRGVDIDNPYFNFITAFTVPDIDDVTVIDFDASEERLYWTDIKTQTIKRAFINGTGLETVISRDIQSIRGLAVDWVSRNLYWISSEFDETQINVARLDGSLKTSIIHGIDKPQCLAAHPVRGKLYWTDGNTINMANMDGSNSKILFQNQKEPVGLSIDYVENKLYWISSGNGTINRCNLDGGNLEVIESMKEELTKATALTIMDKKLWWADQNLAQLGTCSKRDGRNPTILRNKTSGVVHMKVYDKEAQQGSNSCQLNNGGCSQLCLPTSETTRTCMCTVGYYLQKNRMSCQGIESFLMYSVHEGIRGIPLEPSDKMDALMPISGTSFAVGIDFHAENDTIYWTDMGFNKISRAKRDQTWKEDIITNGLGRVEGIAVDWIAGNIYWTDHGFNLIEVARLNGSFRYVIISQGLDQPRSIAVHPEKGLLFWTEWGQMPCIGKARLDGSEKVVLVSMGIAWPNGISIDYEENKLYWCDARTDKIERIDLETGGNREMVLSGSNVDMFSVAVFGAYIYWSDRAHANGSVRRGHKNDATETITMRTGLGVNLKEVKIFNRVREKGTNVCARDNGGCKQLCLYRGNSRRTCACAHGYLAEDGVTCLRHEGYLLYSGRTILKSIHLSDETNLNSPIRPYENPRYFKNVIALAFDYNQRRKGTNRIFYSDAHFGNIQLIKDNWEDRQVIVENVGSVEGLAYHRAWDTLYWTSSTTSSITRHTVDQTRPGAFDREAVITMSEDDHPHVLALDECQNLMFWTNWNEQHPSIMRSTLTGKNAQVVVSTDILTPNGLTIDYRAEKLYFSDGSLGKIERCEYDGSQRHVIVKSGPGTFLSLAVYDNYIFWSDWGRRAILRSNKYTGGDTKILRSDIPHQPMGIIAVANDTNSCELSPCALLNGGCHDLCLLTPNGRVNCSCRGDRILLEDNRCVTKNSSCNAYSEFECGNGECIDYQLTCDGIPHCKDKSDEKLLYCENRSCRRGFKPCYNRRCIPHGKLCDGENDCGDNSDELDCKVSTCATVEFRCADGTCIPRSARCNQNIDCADASDEKNCNNTDCTHFYKLGVKTTGFIRCNSTSLCVLPTWICDGSNDCGDYSDELKCPVQNKHKCEENYFSCPSGRCILNTWICDGQKDCEDGRDEFHCDSSCSWNQFACSAQKCISKHWICDGEDDCGDGLDESDSICGAITCAADMFSCQGSRACVPRHWLCDGERDCPDGSDELSTAGCAPNNTCDENAFMCHNKVCIPKQFVCDHDDDCGDGSDESPQCGYRQCGTEEFSCADGRCLLNTQWQCDGDFDCPDHSDEAPLNPKCKSAEQSCNSSFFMCKNGRCIPSGGLCDNKDDCGDGSDERNCHINECLSKKVSGCSQDCQDLPVSYKCKCWPGFQLKDDGKTCVDIDECSSGFPCSQQCINTYGTYKCLCTDGYEIQPDNPNGCKSLSDEEPFLILADHHEIRKISTDGSNYTLLKQGLNNVIAIDFDYREEFIYWIDSSRPNGSRINRMCLNGSDIKVVHNTAVPNALAVDWIGKNLYWSDTEKRIIEVSKLNGLYPTILVSKRLKFPRDLSLDPQAGYLYWIDCCEYPHIGRVGMDGTNQSVVIETKISRPMALTIDYVNRRLYWADENHIEFSNMDGSHRHKVPNQDIPGVIALTLFEDYIYWTDGKTKSLSRAHKTSGADRLSLIYSWHAITDIQVYHSYRQPDVSKHLCMINNGGCSHLCLLAPGKTHTCACPTNFYLAADNRTCLSNCTASQFRCKTDKCIPFWWKCDTVDDCGDGSDEPDDCPEFRCQPGRFQCGTGLCALPAFICDGENDCGDNSDELNCDTHVCLSGQFKCTKNQKCIPVNLRCNGQDDCGDEEDERDCPENSCSPDYFQCKTTKHCISKLWVCDEDPDCADASDEANCDKKTCGPHEFQCKNNNCIPDHWRCDSQNDCSDNSDEENCKPQTCTLKDFLCANGDCVSSRFWCDGDFDCADGSDERNCETSCSKDQFRCSNGQCIPAKWKCDGHEDCKYGEDEKSCEPASPTCSSREYICASDGCISASLKCNGEYDCADGSDEMDCVTECKEDQFRCKNKAHCIPIRWLCDGIHDCVDGSDEENCERGGNICRADEFLCNNSLCKLHFWVCDGEDDCGDNSDEAPDMCVKFLCPSTRPHRCRNNRICLQSEQMCNGIDECGDNSDEDHCGGKLTYKARPCKKDEFACSNKKCIPMDLQCDRLDDCGDGSDEQGCRIAPTEYTCEDNVNPCGDDAYCNQIKTSVFCRCKPGFQRNMKNRQCEDLNECLVFGTCSHQCINVEGSYKCVCDQNFQERNNTCIAEGSEDQVLYIANDTDILGFIYPFNYSGDHQQISHIEHNSRITGMDVYYQRDMIIWSTQFNPGGIFYKRIHGREKRQANSGLICPEFKRPRDIAVDWVAGNIYWTDHSRMHWFSYYTTHWTSLRYSINVGQLNGPNCTRLLTNMAGEPYAIAVNPKRGMMYWTVVGDHSHIEEAAMDGTLRRILVQKNLQRPTGLAVDYFSERIYWADFELSIIGSVLYDGSNSVVSVSSKQGLLHPHRIDIFEDYIYGAGPKNGVFRVQKFGHGSVEYLALNIDKTKGVLISHRYKQLDLPNPCLDLACEFLCLLNPSGATCVCPEGKYLINGTCNDDSLLDDSCKLTCENGGRCILNEKGDLRCHCWPSYSGERCEVNHCSNYCQNGGTCVPSVLGRPTCSCALGFTGPNCGKTVCEDFCQNGGTCIVTAGNQPYCHCQPEYTGDRCQYYVCHHYCVNSESCTIGDDGSVECVCPTRYEGPKCEVDKCVRCHGGHCIINKDSEDIFCNCTNGKIASSCQLCDGYCYNGGTCQLDPETNVPVCLCSTNWSGTQCERPAPKSSKSDHISTRSIAIIVPLVLLVTLITTLVIGLVLCKRKRRTKTIRRQPIINGGINVEIGNPSYNMYEVDHDHNDGGLLDPGFMIDPTKARYIGGGPSAFKLPHTAPPIYLNSDLKGPLTAGPTNYSNPVYAKLYMDGQNCRNSLGSVDERKELLPKKIEIGIRETVA
Glycosylation Sites
| Position | Description | PubMed ID | GlyTouCan ID | Source |
|---|---|---|---|---|
| 134 | N-linked (GlcNAc...) asparagine |
|
||
| 190 | N-linked (GlcNAc...) asparagine |
|
||
| 220 | N-linked (GlcNAc...) asparagine |
|
||
| 313 | N-linked (GlcNAc...) asparagine | |||
| 360 | N-linked (GlcNAc...) asparagine |
|
||
| 443 | N-linked (GlcNAc...) asparagine |
|
||
| 725 | N-linked (GlcNAc...) asparagine | |||
| 758 | N-linked (GlcNAc...) asparagine |
|
||
| 829 | N-linked (GlcNAc...) asparagine |
|
||
| 883 | N-linked (GlcNAc...) asparagine |
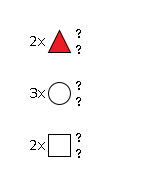 G46910OC
G46910OC
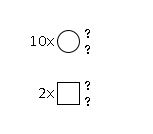 G83460ZZ
G83460ZZ
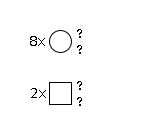 G62765YT
G62765YT
Feature
 : Glycosylation Site from GlyGen
: Glycosylation Site from GlyGen : Glycosylation Site from UniProt
: Glycosylation Site from UniProt
Disease
| DO ID | Disease Name | Source |
|---|---|---|
| DOID:10534 | stomach cancer | |
| DOID:1324 | lung cancer | |
| DOID:1909 | melanoma | |
| DOID:219 | colon cancer | |
| DOID:3083 | chronic obstructive pulmonary disease | |
| DOID:3121 | gallbladder cancer | |
| DOID:3908 | lung non-small cell carcinoma | |
| DOID:3910 | lung adenocarcinoma | |
| DOID:4928 | intrahepatic cholangiocarcinoma | |
| DOID:684 | hepatocellular carcinoma |


